Problemas, erros, bugs e servidores que “não funcionam” - essa é só uma pequena amostra do que administradores, especialistas de segurança da informação e outras áreas encaram no dia a dia. Todos nós precisamos resolver um incidente o mais rápido possível! Mas por onde começar? Onde encontrar a causa e como lidar com ela? Neste material, vamos considerar as principais áreas onde costumam surgir problemas: sistema de arquivos, serviços, units e outros. Como existe uma enorme variedade de falhas possíveis, cada uma tem seu próprio caminho de resolução. Ainda assim, dá para dividir o processo de troubleshooting em duas etapas: analisar e aplicar a solução.

Primeira etapa: análise
Antes de tudo, precisamos identificar o problema e em que área do sistema operacional ele está acontecendo. Às vezes vemos a mensagem de erro diretamente em um programa, utilitário ou serviço. Por exemplo, um sistema de controle de acesso e gerenciamento de contas pode exibir um erro como este:
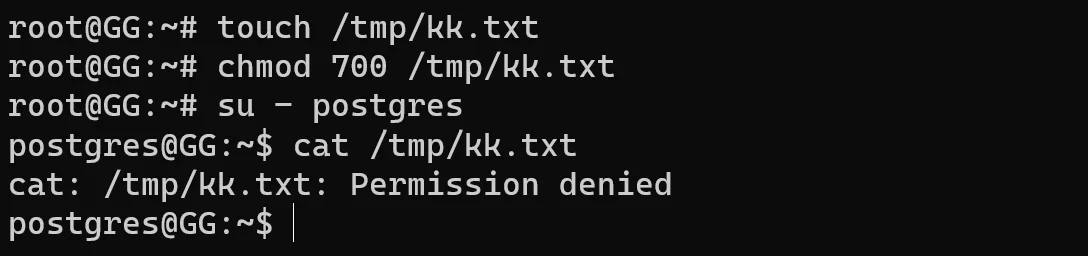
Não temos permissão para acessar um arquivo criado pelo root porque ele está com permissões 700. Isso significa que o root tem permissão rwx, mas outros usuários e grupos não têm. Para resolver esse tipo de problema, ajuste as permissões do arquivo ou diretório necessário. Em outros casos, o sistema pode não “avisar” o que está acontecendo internamente, porque o processo não é interrompido. O sistema operacional funciona como uma caixa-preta com milhões de processos dentro - e precisamos monitorar isso. Para isso existem os logs, que ajudam a entender e resolver incidentes.
Vamos dar uma olhada nos logs do sistema para entender onde as ocorrências são registradas:
journalctl | grep "login" | tailEsse comando usa um pipeline com três etapas: o journalctl lê os logs do sistema; o grep filtra por um padrão de texto no meio de um grande volume de dados; e o tail mostra as últimas linhas. Como resultado, vemos o final do log relacionado a logins do sistema operacional:
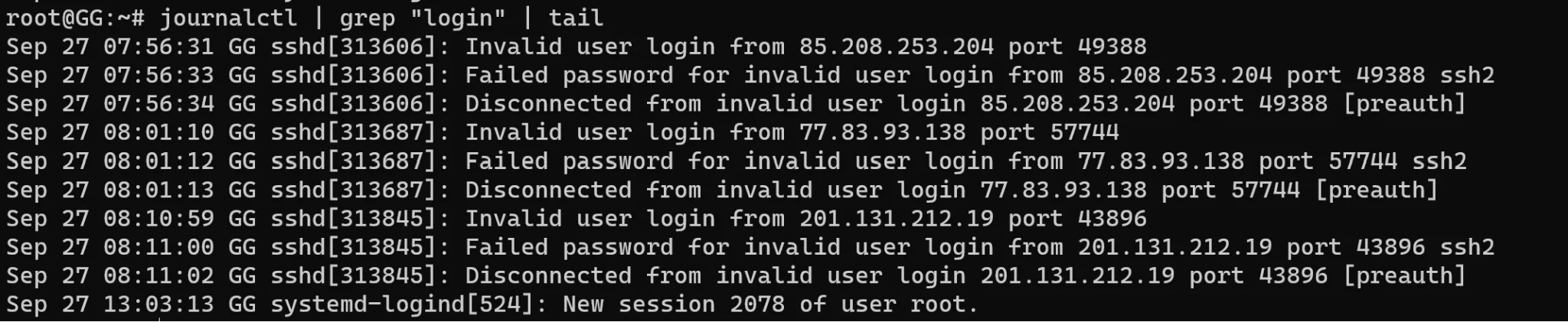
É curioso observar que, no servidor usado para testes, não configuramos chave pública - e dá para ver uma causa comum de problemas: vários endereços IP tentando acessar a máquina. A recomendação aqui é configurar uma chave pública confiável. Isso ajuda a identificar a origem do problema.
Também podemos usar o journalctl para verificar o status de um serviço específico. Se você encontrar um erro relacionado, por exemplo, ao PostgreSQL, execute:
journalctl -xeu postgresql@15-main.service
Pelas recomendações acima, também é possível checar o journal de units (unidades) e ações:

Na tela acima, vemos o campo Subject com a mensagem “Unit failed” e uma linha marcada como FATAL. Nesse caso, o problema costuma estar nos arquivos de configuração, e por isso a unit não consegue iniciar.
Segunda etapa: solução
Se você quer verificar os serviços e seus status, use:
systemctl list-units -t service -p important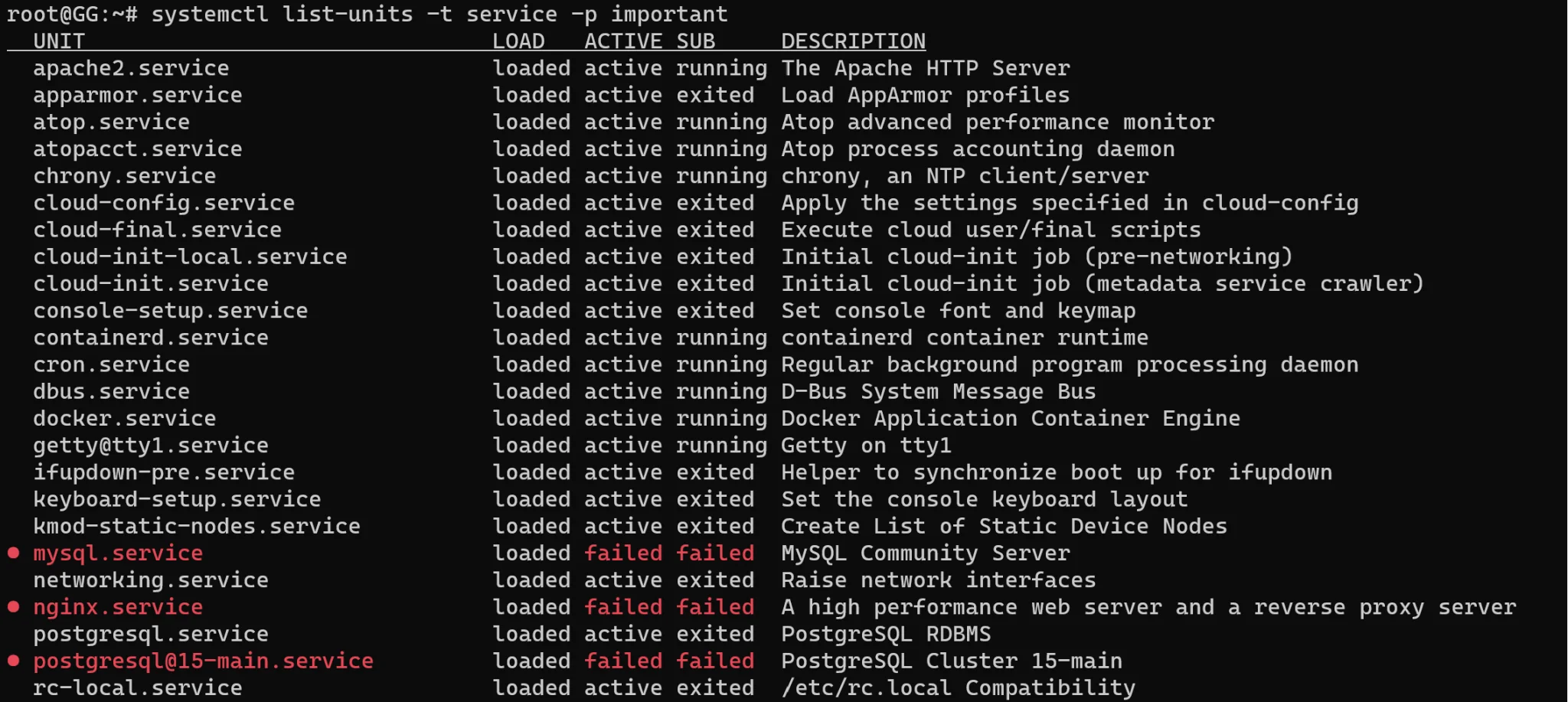
Vamos fazer troubleshooting do serviço PostgreSQL: abra o arquivo de configuração e procure a linha com erro:

Remova a linha com problema usando o atalho Ctrl + K, salve o arquivo e reinicie o serviço:
systemctl restart postgresql@15-main.serviceEm seguida, verifique o status:
systemctl status postgresql@15-main.service
Dependendo do seu caso, talvez você precise de passos mais específicos. Uma forma prática é pesquisar a mesma mensagem de erro em um mecanismo de busca ou em ferramentas de IA generativa, como o GPT. Neste artigo, estamos focando em ferramentas de monitoramento e diagnóstico para ajudar a resolver erros.
Se você não conseguir encontrar a causa do problema, mas perceber que a máquina está lenta, pode instalar um “gerenciador de tarefas” para terminal, como o atop:
apt install atop -yDepois, execute o atop e aguarde a janela com os processos em execução:
atop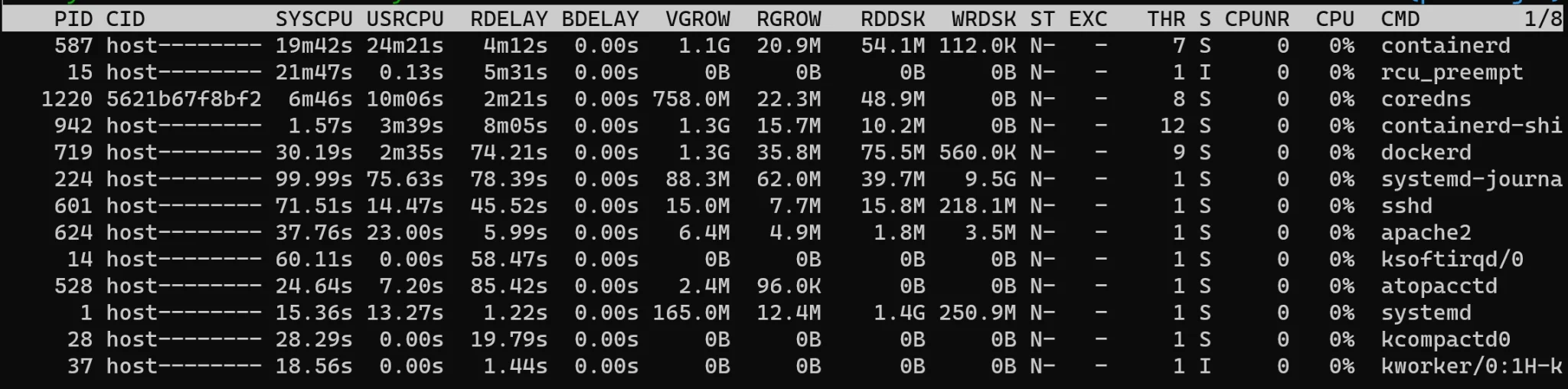
Na última coluna, é possível ver o campo de CPU com o percentual de uso do processo naquele momento. Se você identificar uma carga alta, pode encerrar ou interromper o processo. Por exemplo:
kill -SIGINT 332697E um segundo comando para finalizar:
kill -SIGTERM 332697
Se o terminal não retornar mensagem de erro, significa que o comando foi executado com sucesso.
Erros e desafios em sistemas baseados em Debian fazem parte da rotina de administração. Este guia abordou diferentes formas de identificar e resolver problemas com mais eficiência, usando logs, diagnóstico de serviços e ferramentas de monitoramento.


