Introdução
Configure a integração contínua e automatize os pipelines de teste com a sintaxe declarativa componível do Concourse CI. Em comparação com outros sistemas para configurar a integração contínua, a equipe do Concourse faz todos os esforços para simplificar o gerenciamento do pipeline de integração contínua.

As instruções anteriores analisaram o download e a configuração do Concourse em um servidor Ubuntu 22.04 e protegeram nossa interface da Web com SSL de uma CA Let's Encrypt.
Neste tutorial, veremos como usar o Concourse para executar testes automaticamente, e as alterações serão confirmadas em nosso repositório.
Considere a possibilidade de configurar um pipeline de integração contínua com o aplicativo "hello world", usando o código Hapi.js, criado na estrutura da Web do Node.js para garantir o processo de sincronização do código com a montagem e os testes. Vamos adicionar definições de CI ao próprio repositório do produto. Vamos usar o terminal e o utilitário "fly" para iniciar o pipeline no Concourse. Por fim, vamos adicionar as alterações ao nosso repositório para salvá-las e implementar os testes no fluxo de trabalho de CI.
Preparação para o trabalho
Antes de começar, você precisa executar um servidor baseado no Ubuntu/Debian/CentOS, a RAM deve ter pelo menos 1 GB.
Defina as permissões do usuário para executar com sudo.
Baixe e instale o utilitário Concourse do site oficial ou do GitHub e o servidor da Web Nginx instalado usando o gerenciador de pacotes. Você precisa configurar um certificado de segurança TLS/SSL, configurar um servidor proxy reverso para a interface da Web do Concourse.
Precisamos obter um nome de domínio que aponte para o nosso servidor Concourse.
Use as instruções a seguir para a configuração adequada:
- Instalando e configurando o servidor com um usuário padrão;
- Instalar o Concourse CI;
- Instalar e configurar o Nginx;
- Configurando a segurança do Concourse CI com SSL;
Neste manual, todo o processo de trabalho é considerado em um computador funcional com o Ubuntu Linux pré-instalado. Por esse motivo, você deve se certificar de que instalou vários utilitários para editar arquivos de texto que sejam convenientes para você usar.
Você também precisará do utilitário Git em seu computador local e seguirá nossas instruções para a configuração adequada.
Quando tivermos certeza de que o servidor Concourse está em execução e que o computador local tem todas as ferramentas para trabalhar com arquivos de texto e o Git está instalado, vamos prosseguir para a tarefa principal de nossas instruções.
Usando o Fly na linha de comando
Você precisa ter certeza de que o Concourse Worker e o Fly estão instalados no servidor principal (para gerenciar o pipeline usando a linha de comando).
Para o trabalho diário com o Concourse CI, é mais conveniente instalar o fly em um computador de trabalho, que tem ferramentas diárias para trabalhar com o desenvolvimento de vários produtos.
Para obter a versão mais recente do fly, você precisa abrir a interface da Web do Concourse CI instalada no servidor:
https://server_urlApós a autorização no servidor, na parte inferior direita da tela, você pode fazer o download do fly selecionando seu sistema no local de trabalho:

Clicamos no ícone do nosso sistema local e fazemos o download para um diretório conveniente para nós, que no nosso caso é Downloads.
Linux e MacOS
Se sua estação de trabalho principal tiver Linux ou um dispositivo com MacOS, siga estas etapas para instalar e executar o Fly:
chmod +x /root/flyEm seguida, você precisa adicionar o utilitário fly ao ambiente "PATH" para executá-lo no terminal:
install /root/fly /usr/local/binVamos executar o utilitário fly e obter informações sobre a versão:
fly –versionObtemos um resultado que corresponde à versão da interface da Web:
7.9.0Windows
Se o sistema primário for uma estação de trabalho Windows, você precisará executar o PowerShell e adicionar o diretório bin:
PS C:UsersServerspace> mkdir binVocê precisa copiar o utilitário fly.exe baixado para o diretório bin:
PS C:UsersServerspace> mv .Downloadsfly.exe .binVamos verificar a relevância do perfil executando o comando:
PS C:UsersServerspace> Test-Path $profileSe o resultado for True, o perfil atual está disponível no sistema.
Se o resultado for False, você precisará criar um novo perfil:
PS C:UsersServerspace> New-Item -path $profile -type file -forceComo resultado, temos:
Directory: C:UsersServerspaceDocumentsWindowsPowerShell
Mode LastWriteTime Length Name
---- ------------- --------- ----
-a---- 31.01.2023 18:05 0 Microsoft.PowerShell_profile.ps1Vamos abrir o arquivo de perfil do editor de texto Notepad criado:
PS C:UsersServerspace> notepad.exe $profileUma nova janela do editor de arquivos de texto será aberta e adicionada ao ambiente PATH, especificando o caminho para o arquivo:
$env:path += ";C:UsersServerspacebin"Salve o arquivo e saia.
Vamos começar a ler o caminho de $profile:
PS C:UsersServerspace> . $profileEm seguida, execute o comando para verificar a versão do arquivo fly baixado:
PS C:UsersServerspace> fly.exe –versionComo saída, obtemos:
7.9.0Ao executar comandos do Windows, você precisa alterar cada comando fly (neste tutorial) para fly.exe.
Autorização usando a linha de comando
Depois de iniciar o fly com sucesso, você precisa fazer login no Concourse instalado. Cada servidor pode usar vários "alvos", com os quais você pode identificar o pipeline necessário no sistema e executar comandos nele.
Neste tutorial, vamos dar uma olhada no tutorial no nome de destino do sistema Concourse:
fly -t tutorial login -c https://concourse_server_urlÉ necessário preencher o login e a senha do arquivo de configuração /etc/concourse/web_environment do nosso servidor.
Como resultado, temos:
logging in to team 'main'
username: serverspace
password:target saved
Se a autorização for bem-sucedida, um arquivo .flyrc aparecerá em seu diretório pessoal.
Vamos verificar a criação do "tutorial" no .flyrc:
fly -t tutorial syncComo resultado, obtemos:
version 7.9.0 already matches; skippingForking e clonagem de um repositório
Depois de configurar o fly, você precisa configurar o repositório para usar os pipelines do Concourse.
Em um navegador da Web, abra o link para o repositório, que usaremos em nossas instruções.
No Concourse, você precisa adicionar um pipeline de integração contínua à filial principal do repositório.

No terminal, vá para o diretório do usuário. Vamos fazer uma cópia do repositório em nosso computador de trabalho. Para isso, usaremos os seguintes comandos do utilitário git clone e iremos para uma nova ramificação:
cd
git clone https://github.com/githubUser/hello_hapi
cd hello_hapi
git checkout -b pipelineApós a execução dos comandos, obtemos a seguinte linha:
Switched to a new branch 'pipeline'Mudamos para uma nova ramificação.
Configurar a integração contínua para um aplicativo
Vamos definir nossos arquivos que estão associados ao repositório do projeto. Assim, garantiremos a sincronização do trabalho de integração contínua com o código em teste.
O conjunto de testes está localizado no diretório de testes. Ele contém três testes. O script de teste reside em package.json, que armazena o elemento de teste no objeto scripts.
É necessário criar um diretório chamado ci e definir duas subpastas denominadas tasks e scripts, nas quais colocaremos os arquivos de integração contínua do produto.
Vamos executar o seguinte comando:
mkdir -p ci/{tasks,scripts}Adicionando um pipeline
No diretório ci, criaremos um arquivo chamado pipeline.yml, no qual especificaremos nossas definições de configuração:
vim ci/pipeline.ymlDepois de criar o arquivo de configuração para o pipeline principal, precisamos adicionar nossa configuração a ele.
Definição do cache NPM
Vamos adicionar a seguinte configuração:
---
resource_types:
- name: npm-cache
type: docker-image
source:
repository: ymedlop/npm-cache-resource
tag: latestOs processos que se desacoplam dos dados de integração contínua são processados pelo Concourse e extraem as informações de status da abstração e são convertidos em recursos.
Os recursos são dados de origem para o Concourse usar ao receber ou enviar informações.
A string resource_types definirá novos tipos de recursos que você pode implementar em seu pipeline.
Definição e armazenamento em cache de um repositório
Adicione o seguinte trecho de código ao pipeline.yml para definir o recurso real para o pipeline:
resources:
- name: hello_hapi
type: git
source: &repo-source
uri: https://github.com/githubUser/hello_hapi
branch: master
- name: dependency-cache
type: npm-cache
source:
<<: *repo-source
paths:
- package.jsonO primeiro dos recursos define nossa ramificação do repositório. Source define a ligação YAML para o nome da fonte do repositório.
O primeiro recurso mostra a ramificação do nosso repositório do GitHub.
O segundo recurso define uma "cache-dependency" que usará o tipo de recurso "npm-cache" e determinará a execução do download das dependências necessárias do projeto.
A cadeia de caracteres "source" é seguida por <<: *repo-source é usada para redirecionar e expandir itens. No final, escrevemos "paths", que se refere ao pacote package.json baixado anteriormente.
Teste de dependência
Vamos definir os processos reais de integração contínua usando os trabalhos do Concourse. No final da configuração pipeline.yml, adicione o seguinte trecho de código sem excluir as linhas de código anteriores:
jobs:
- name: install_dependencies
plan:
- get: hello_hapi
trigger: true
- get: dependency-cache
- name: run_tests
plan:
- get: hello_hapi
trigger: true
passed: [install_dependencies]
- get: dependency-cache
passed: [install_dependencies]
- task: run_the_test_suite
file: hello_hapi/ci/tasks/run_tests.ymlO código implementará dois trabalhos. Cada tarefa contém um nome e um plano. O plano armazena elementos como "receiving" e "setting". A primeira das instruções get recupera dados do repositório e define o parâmetro trigger como true.
O segundo Get (dependency-cache) inclui um recurso específico para fazer download e armazenar em cache as dependências necessárias do Node.js no projeto.
O operador Get precisa avaliar os requisitos do package.json e, com base nisso, o operador carrega os dados.
Há também uma instrução "passed" no código, que atribui à instrução get os elementos que passaram pelas etapas anteriores com um resultado bem-sucedido, a fim de unir os processos em pipeline.
No final de todas as instruções, é formada uma linha com um link para "run_tests.yml", para extração e execução de testes. A próxima etapa é criar esse arquivo.
Criação de tarefas de teste
O processo de extração de tarefas o ajudará a manter a definição do pipeline concisa e fácil de ler.
Você precisa criar um novo arquivo de configuração no diretório ci/tasks chamado run_tests.yml:
vim ci/tasks/run_tests.ymlPara transferir as tarefas de teste, é necessário preencher a linha com a plataforma de acordo com o nosso sistema no qual o processo de trabalho do desenvolvedor é realizado; também indicamos a imagem que qualquer entrada ou saída pode definir para uso na tarefa. No final, especifique o caminho para o arquivo executável.
Adicione o seguinte trecho de código para configurar uma tarefa para teste:
---
platform: linux
image_resource:
type: docker-image
source:
repository: node
tag: latest
inputs:
- name: hello_hapi
- name: dependency-cache
run:
path: hello_hapi/ci/scripts/run_tests.sh
O arquivo run_tests.yml contém as tarefas que serão executadas no Linux. O Concourse satisfaz as linhas de código acima sem nenhuma configuração adicional.
Você deve especificar uma imagem para usar o "worker" ao executar as tarefas. No entanto, poderemos criar tipos de imagem personalizados e usá-los. A mais comumente usada é a mais famosa imagem do Docker.
Como nosso repositório consiste em um aplicativo Node.js, selecionaremos a imagem "node" ao executar nossos testes porque ela tem todas as ferramentas necessárias.
Para o Concourse, você pode definir entrada e saída para tarefas a fim de especificar os recursos que podem ser usados para acessar os artefatos que elas criarão.
Os recursos devem corresponder às entradas recuperadas anteriormente no nível do "trabalho". Isso torna todos esses recursos disponíveis para o ambiente da tarefa como um diretório de nível superior que pode ser manipulado durante a execução da tarefa.
Neste manual, consideramos um aplicativo que está localizado no diretório hello_hapi baixado anteriormente. As dependências do Node.js são armazenadas no diretório dependency-cache.
A etapa de execução de um script com um script às vezes requer a movimentação de arquivos ou diretórios para o local esperado especificado no script e a colocação de artefatos em locais de saída no final das tarefas.
O script contém o comando a ser executado. Cada tarefa armazena um comando com um argumento, portanto, vamos criar um script bash para executar os comandos. Mas, geralmente, o caminho para o arquivo com o script de comando é indicado na tarefa. No nosso caso, especificamos o caminho para o script no diretório hello_hapi, que está localizado em hello_hapi/ci/scripts/run_tests.sh.
Na próxima etapa, considere a criação de um arquivo de script.
Você precisa salvar e sair.
Criando um arquivo de script
Agora precisamos criar um arquivo de script que execute nossos testes. Você precisará fazer alterações usando um editor de texto.
touch ci/scripts/run_tests.sh
vim ci/scripts/run_tests.shEsse script conterá dados para o ambiente de teste e moverá os elementos para o diretório desejado. Em seguida, os testes dos repositórios especificados serão executados e o npm test será executado.
Use o código a seguir para executar os testes:
#!/usr/bin/env bash
set -e -u -x
mv dependency-cache/node_modules hello_hapi
cd hello_hapi && npm test
Saia e salve usando :wq!
Em primeiro lugar, o caminho para o interpretador de comandos é indicado para a execução de comandos desse arquivo. Vamos definir os parâmetros padrão para interromper o script quando forem encontrados erros e em variáveis. Assim, o script é executado de forma segura e temos uma boa visibilidade da depuração.
Mv (mover) move as dependências do cache de node_modules para o diretório inicial de hello_hapi.
Em seguida, vá para o diretório inicial do projeto e execute o npm test.
Depois de escrever o código em um arquivo, você deve salvar e sair.
Você precisa atribuir permissões para executar run_tests.sh no diretório ci/scripts:
chmod +x ci/scripts/run_tests.shApós a atribuição de direitos, nosso pipeline está pronto para ser executado.
Executando um pipeline no Concourse
Antes de fazer o merge do branch do pipeline no branch principal e exportá-lo para o GitHub, precisamos fazer o upload do pipeline para o Concourse. Ele também processa nosso repositório para detectar alterações e executa uma rotina de integração contínua quando detectado.
Você deve iniciar manualmente o pipeline usando os comandos do utilitário fly baixado anteriormente.
Especificamos o destino por meio do parâmetro -t, adicionamos um pipeline e, após o parâmetro -p, inserimos o nome e usamos -c para apontar para o arquivo do qual os dados do pipeline serão recuperados:
fly -t tutorial set-pipeline -p hello_hapi -c ci/pipeline.ymlConcordamos com o lançamento:
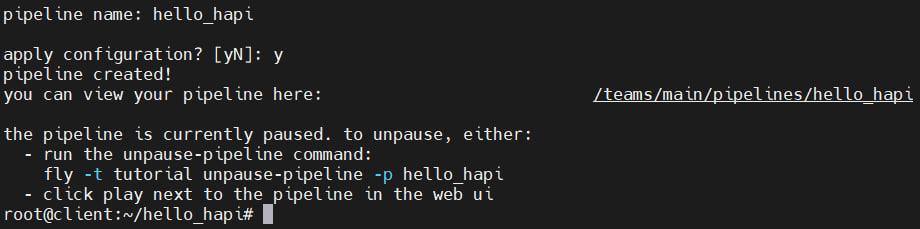
Depois de adicionar um pipeline com sucesso, ele é pausado. A retomada do trabalho ocorre por meio da interface da Web ou da execução do comando:
fly -t tutorial unpause-pipeline -p hello_hapi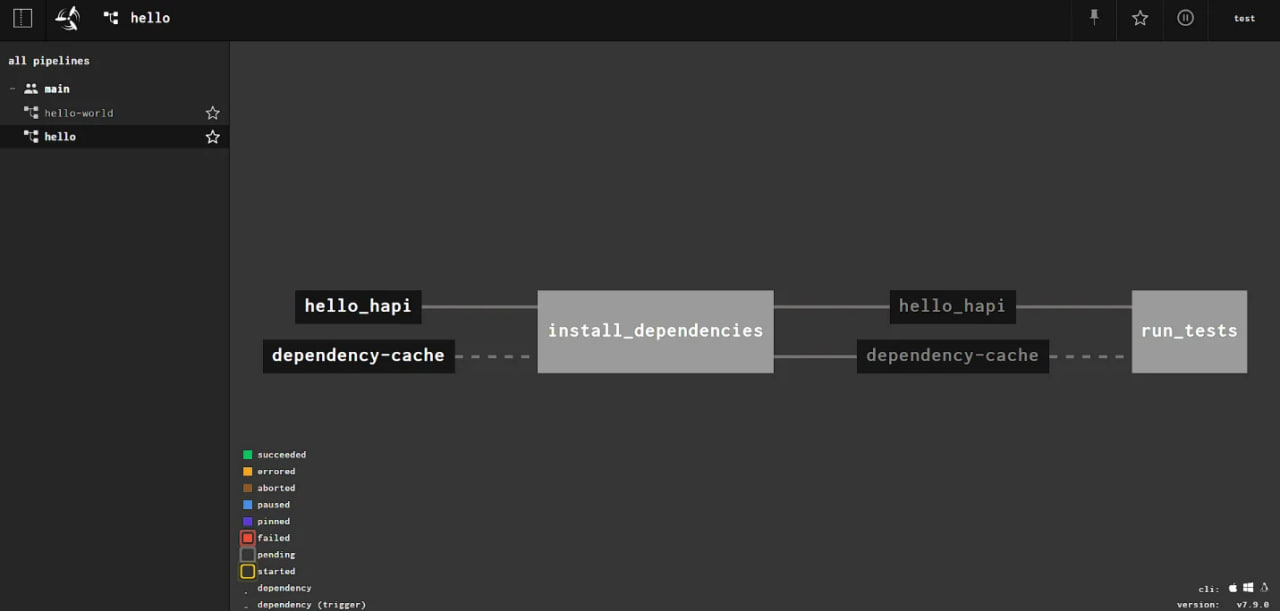
Também na interface da Web, você pode usar o botão para iniciar o pipeline.
Comprometendo alterações no Git
Depois de iniciar o processo de integração contínua, precisamos adicionar alterações ao nosso repositório Git.
Adicionando o diretório ci ao git:
git add ciVocê precisa verificar o status dos arquivos adicionados:
git status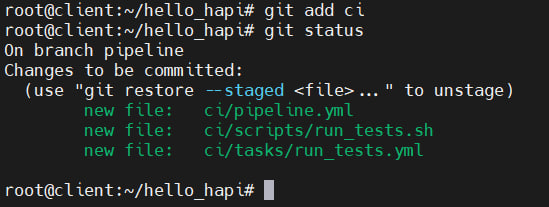
Vamos confirmar as alterações e usar o comando:
git commit -m 'First commit for our project'Precisamos mesclar nossas ramificações mudando para a ramificação principal.
git checkout master
git merge pipeline
Precisamos confirmar as alterações que fizemos em nosso repositório:
git push origin masterÉ importante observar que, depois de salvar todas as alterações, você precisa executar o teste em um minuto.
Visão de execução do teste
Ao retornar à interface da Web, você precisa iniciar um novo teste clicando no botão +:
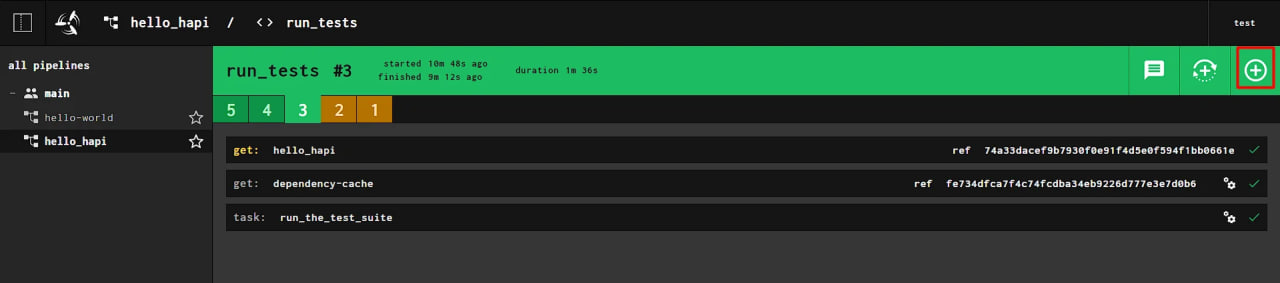
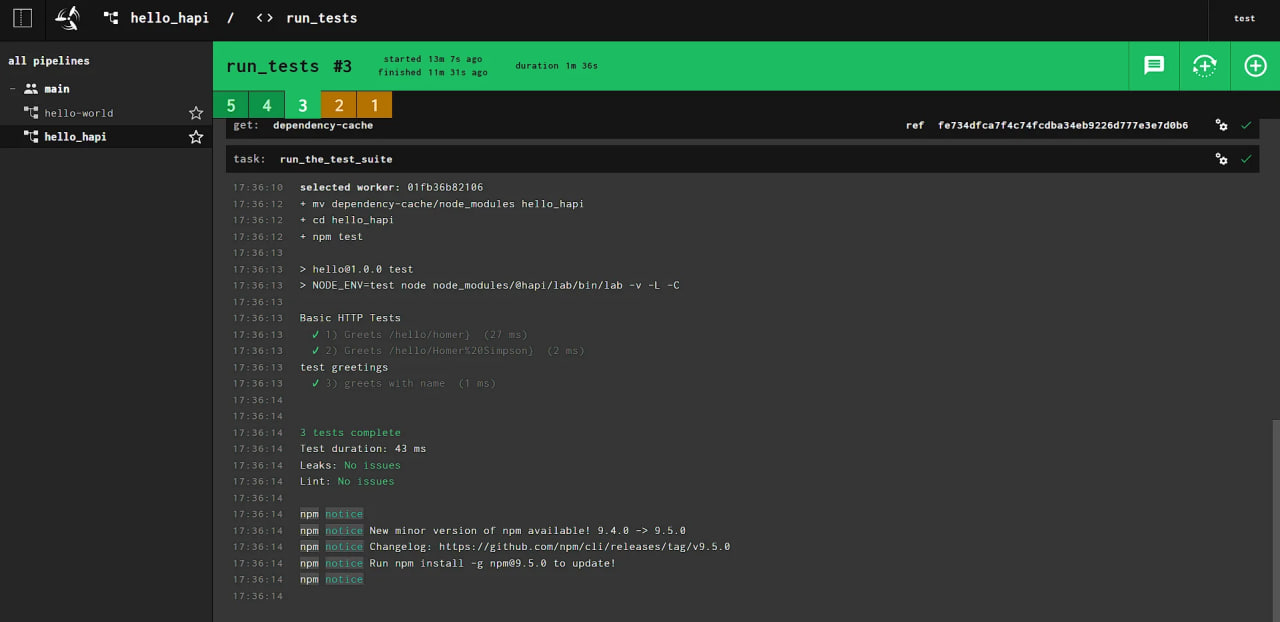
Os dois primeiros testes estão marcados em amarelo porque não interagiram com o repositório Git. Depois de adicionar novos testes, você pode clicar na tarefa (tarefas) e ver os resultados do teste.
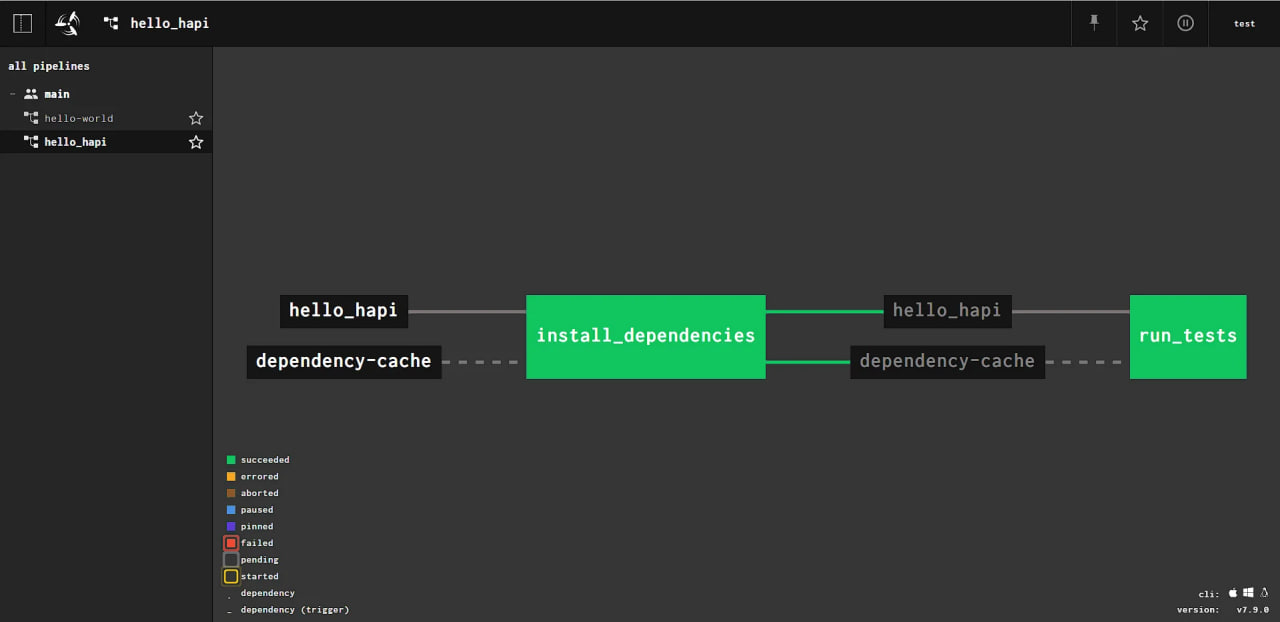
Se você clicar na inscrição hello_hapi, poderá retornar ao estado inicial do pipeline e ver o resultado da execução do pipeline:
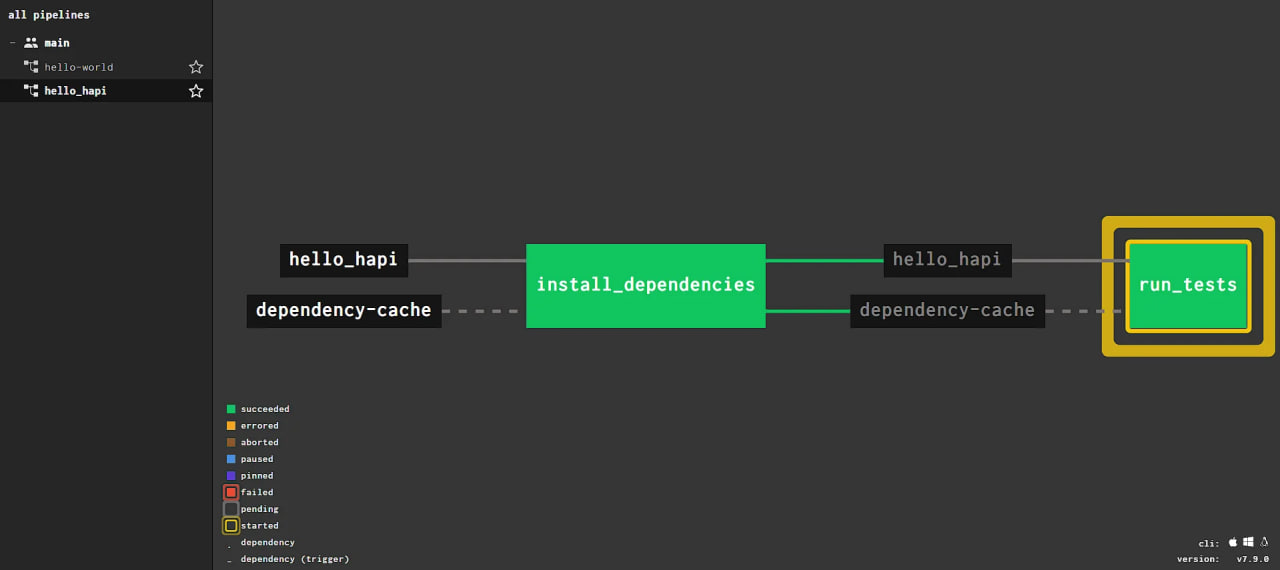
Os quadrados amarelos ao redor de uma tarefa significam que uma nova tarefa está sendo iniciada:
Conclusões
Neste guia, abordamos:
- configuração do utilitário fly;
- clonagem de um repositório do Git;
- criação de um script para o transportador;
- criação de um script para testes;
- iniciar o transportador;
- fazendo alterações em nosso repositório;
- execução de testes.


